

Lean removed waste and stabilised processes. In 2026, augmentation changes the operating model, so your outsourcing partner must prove adoption visibility, defensible QA, drift control, evidence trails, and workflow embedding before you scale.
If you spent the last two years stabilising your contact centre with Lean or Six Sigma frameworks, you already know what clean operations look like. Waste is reduced. Escalation paths are documented. SOP adherence is measurable. That work mattered, and it still does.
But in 2026, it is not enough.
The outsourcing evaluation question has shifted. You are no longer asking whether a vendor can run structured workflows. You are asking whether a vendor can run an augmented operating model — one where AI sits inside agent workflows in real time, automated scoring is applied across voice, email, and chat, and daily operational health depends on adoption, calibration, and drift control rather than headcount.
If you’re leading a blended inbound + outbound operation and you’ve already started piloting agent assist and/or automated QA, you’ve probably discovered an uncomfortable truth: the fastest way to “scale AI” is also the fastest way to scale inconsistency.
The contact centre technology stack is now an ecosystem, not a phone system, and real performance depends on how well automation and people actually collaborate inside daily workflows. That’s not trend commentary. It’s a buying reality: it changes what you should demand from an outsourcing partner.
This is the 2026 standard: augmentation must be measurable, governable, and auditable, or it becomes noise, disputes, and regression you can’t explain to leadership.
Section 1: After Lean, the Work Moves Inside the Workflow
Buying question this post answers: How do I evaluate an outsourcing partner when “quality” and “productivity” are now partially mediated by agent assist and automation-enabled QA?
After Lean, the Work Moves Inside the Workflow
Lean did what it was supposed to: clarified CTQs, reduced rework, stabilised handoffs, standardised response templates, and made variance visible.
But augmentation changes the challenge.
In a Lean-only model, you controlled quality primarily through:
- standard work + coaching
- calibrated scorecards
- sampling + audits
- continuous improvement loops
In an augmented model, you still need those, but control also moves into live interactions:
- agent assist influences what gets said, what gets captured, and what gets skipped (especially on outbound compliance and inbound triage)
- automation-enabled QA influences what gets coached, what gets escalated, and what leadership sees as “truth”
- workflow embedding determines whether any of it sticks (or dies in tab-switch friction)
Now the risk is not a broken process, it is a functioning process that quietly underperforms because AI adoption is inconsistent, scoring outputs are distrusted, or policy changes go undetected in live agent behavior.
This is why vendor selection is no longer just: SLAs + staffing model + cost per contact. It’s: “Does this partner run an augmented operating model with evidence and controls?” This is not a technology problem. It is an operating model problem. The vendors who can solve it are the ones who have built governance, not just deployment, around their AI tooling.
The industry has already moved toward agent assist and automated quality management as foundational technologies.
Section 2: The Augmented Contact Center stack
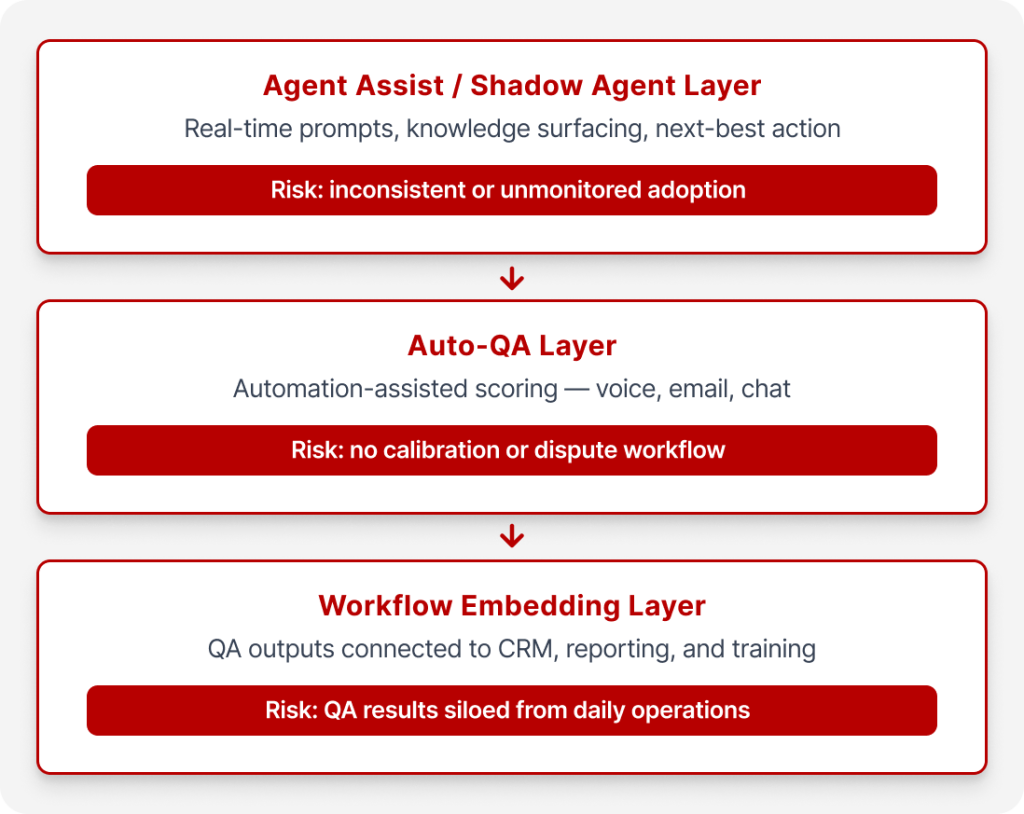
Think of the augmented contact centre as a three-layer stack. Your outsourcing partner operating at the 2026 standard should be able to operate all three on a coordination model, or clearly define what they own vs what stays on your side.
Layer 1 — Real-Time Agent Assist. This layer sits inside the live call or message thread. Agent assist isn’t a “nice-to-have” sidebar. In mature deployments, it behaves like a real-time copilot: surfacing relevant knowledge, suggesting approved responses, flagging disclosure or compliance requirements, supporting data capture and suggesting next-best actions based on conversation context.
The risk is not capability, it is adoption. An agent who ignores prompts, routes around them, or uses them inconsistently produces outcomes that look like unaugmented work, regardless of what the system offers.
What to demand from a partner at this layer:
- Clear visibility into usage, not just availability (prompt views, accept/ignore rates, and override reasons)
- A governance model for what content is “allowed” (scripts, disclosures, policy language)
- A plan for how agent assists fits into inbound + outbound realities (triage accuracy and compliance consistency)
Layer 2 — Automation-Enabled QA / Auto‑QA across channels. Automated quality management is positioned in the market as a response to the limitations of manual QA sampling and the need for faster coaching loops. This layer applies automated scoring across voice, email, and chat interactions.
Here’s the procurement-safe truth: Auto‑QA only helps if people trust the audits and the evidence — and if your programme has a disciplined calibration and dispute workflow.
Today AI-first BPO’s like Flatworld, integrate automation and AI-assisted auditing into the quality workflow as a paid, configurable add-on. Such AI-powered BPO’s work on a model where auditing is sample-based, Human review remains part of the control and is configurable. They offer QA manager override + re-audit are available, with audit logs/trails and RBAC support for client stakeholders.
The risk here is not automation itself, it is automation without calibration, without dispute handling, and without evidence trails that agents and managers can actually read.
Layer 3 — Workflow Embedding (CRM/dialler/reporting/training integration).
This layer connects quality outputs to the systems your operations team actually uses: CRM and helpdesk integration, reporting automation, and training workflows built from real interaction data. Without this layer, Auto-QA results live in a silo and coaching lags by weeks.
This is where most “AI rollouts” quietly fail: the tool works, but the work doesn’t change because:
- agents have to leave the desktop to find answers
- QA outputs don’t feed coaching or reporting systems cleanly
- knowledge updates aren’t versioned, so “policy truth” drifts by channel and by team risk is operational friction, QA produces findings that never reach the agents or the workflows they need to change.
Section 3: What Breaks First — Three Failure Modes to Evaluate
You don’t lose value because the model “isn’t smart”. You lose value because execution breaks in predictable ways.
Failure Mode One – Adoption Failures: In 2026, you can’t accept “we rolled it out” as adoption. Usage without consistent adoption is fake adoption. Override rates matter. If agents are ignoring suggestions or routing around the assist layer at high rates, the system is producing noise, not performance lift.
Vendor test: Ask for the adoption telemetry the partner can provide inside your workflow. If they can’t show usage and override patterns, you’re piloting blind.
You need proof that augmentation is being used when it matters:
- Are reps using agent assist on high-risk outbound calls, or only on easy inbound?
- Are they ignoring prompts and still hitting AHT targets — while compliance and diagnosis degrade?
- Are supervisors coaching against what actually happened, or what the dashboard implies?
A vendor operating at this standard should be able to show you adoption instrumentation: usage rates, override rates, and override reason taxonomy, not just that the tool is deployed.
Failure Mode Two: Trust and Calibration Failures: The fastest way to destroy the value of Auto-QA is to deploy it without the calibration and dispute infrastructure that makes scores defensible. Automation-enabled QA fails when scores feel arbitrary, when agents can’t see why they were marked down, or when disputes become political instead of evidentiary.
“Automated QA is trusted if each score includes clear evidence as to what elements of the conversation prompted which rules. Teams have to see exact phrases, response times, or policy violations that created the score. Without transparency, scores appear to be arbitrary. The mistake teams make is deploying automated QA without a structured dispute workflow. If agents can’t challenge scores or understand the reasoning, the system becomes friction instead of insight.” — Paul DeMott
CTO, Helium SEO
In a mature augmented delivery model, weekly calibration cycles are built into the quality workflow. Disputes escalate to human review and documented resolution. Clients can access audit logs directly through role-based access. Evidence trails are not optional, they are the governance layer that makes scoring credible.
Vendor test: You are not buying “Auto‑QA.” You are buying a QA governance system:
- evidence attached to audit outcomes
- calibration that quantifies variance (system vs human, vendor vs client)
- a dispute workflow with documented resolutions
- RBAC so stakeholders see what they should, and only what they should
Failure Mode Three: Drift and Regression Failures: Performance degradation after a policy change, a product update, or a seasonal process shift is one of the most common and least-instrumented risks in outsourced contact centers.
The NIST AI Risk Management Framework highlights that AI systems may be trained on data that changes over time, affecting functionality and trustworthiness in hard-to-detect ways — which increases the need for controls and ongoing risk management.
In contact centres, drift doesn’t always look like a “model problem”. It looks like:
- a new promo, fee, or compliance script rolling out unevenly
- KB updates landing in email templates but not in chat macros
- outbound objection handling slowly shifting off-policy because closure pressure changes behaviour
This is why versioning and re-audit matter in real operations:
“My non-negotiable control is calibration and dispute workflow with versioned scoring rules and re-score on updates. If a vendor can’t re-audit prior interactions after a rule change, you end up coaching people on yesterday’s standards.” — Owner, iRepair Heating and Air
SOP and knowledge-base grounding with versioned updates, combined with sample-based auditing and re-audit capability after rule changes, is the mechanism that prevents drift from becoming invisible. Raw audit data can be exported in CSV for independent analysis or integration into your own reporting environment.
Section 4: The 2026 Scorecard — Measuring Augmentation, Not Speed

Traditional contact center KPIs such as AHT, FCR, CSAT, were designed for an unaugmented operating model, they still matter; They just do not capture the new failure modes or tell you whether the augmented model is stable.
The scorecard your vendor should be reporting against in 2026 includes:
Adoption Visibility (agent assist + workflow embedding)
• Agent-assist usage rate by queue/campaign (not global averages): what percentage of eligible interactions actually used the assist layer
• Accept/ignore/override rate with a reason taxonomy (compliance concern, irrelevance, wrong KB, tone mismatch) – why agents bypassed suggestions and how frequently
• “Workflow friction” indicators (time in non-CRM tabs, manual copy/paste, wrap-up lag proxies)
QA Trust and Calibration (Auto QA in production)
• Auto-QA calibration agreement — variance between human and system scores by category
• Dispute rate and resolution time — how often scores are challenged and how quickly they are resolved
• Percent of audits that receive secondary human review
This is what regulated and high-accountability buyers are now explicitly requiring:
“My hard requirement is calibration with dispute handling tied to a locked gold set… [and] a documented resolution.” — Majority Owner, MitchellJoseph Insurance Agency
Drift and Regression Controls
• Re-audit cadence after rule/SOP updates — how quickly prior interactions are re-scored after policy changes
• Percentage of score changes after manager override/re-audit (signal of calibration health)
• Leakage / recontact rate (inbound) — unresolved issues returning to the queue
• Compliance drift rate (outbound) — disclosure and adherence degradation over time
• Reporting lag — time from interaction to coaching-ready QA output
“My hard requirement is calibration with dispute handling tied to a locked gold set of interactions. I want a monthly workflow where my QA lead and the vendor both score the same fixed set, the system shows variance by category, and agents can file a dispute that forces a human review and a documented resolution. A bad auto-QM score becomes toxic fast if the agent can’t see exactly why it happened and get it corrected.” — Majority Owner, MitchellJoseph Insurance Agency
Evidence and Auditability
• Audit trail availability (what was scored, why, and who changed it)
• RBAC coverage for client stakeholders
• Exportability: dashboards plus raw CSV for independent validation
Reporting at this operational level runs through a structured dashboard environment. Raw data can be provided as CSV export for teams that need to integrate results into their own BI environments.
Section 5: Operating model: who owns what in a partner-led delivery
When you outsource augmented operations, you’re not just outsourcing labour, you’re outsourcing parts of the control system. That’s why ownership must be explicit.
In a shortlist evaluation, require a simple ownership map across four roles:
Augmentation owner/ Ops Lead (day-to-day performance)
Owns adoption measurement, override analysis, queue/campaign performance, and the escalation path when agent assist isn’t being used or is being actively resisted.
QA governance owner (calibration + disputes)
Owns calibration design, dispute workflow, manager override rules, and re-audit triggers after scoring logic changes.
Knowledge owner (SOP/KB grounding + version control)
Owns KB updates, versioning, and the procedural link between policy changes and re-audits/coaching.
Reporting and evidence owner (Power BI, exports, audit trails, RBAC)
Owns stakeholder access, audit logs/trails availability, evidence packaging for reviews, and raw export processes.
The governance cadence that supports this model includes threshold-driven corrective action triggers, disputes that escalate to training or client clarification as appropriate, and configurable human review layers where risk or complexity requires it. QMS deployment for a defined scope can typically be completed in roughly one week depending on requirements and integration complexity.
Section 6: The 2026 Vendor Test – What to Demand from an Outsourcing Partner
At shortlist stage, the evaluation is straightforward: can the vendor demonstrate each of these, or only describe them?
Adoption Visibility
• Show agent-assist adoption metrics by queue/campaign (usage + overrides), not anecdotes.
• Show what the partner does when adoption stalls (measurement → coaching → workflow changes).
Defensible Auto QA
• Confirm whether Auto QA is included or an add-on, and what channels are covered (voice/email/chat).
• Confirm audit coverage: sample design, what triggers human review, and when manager override applies.
• Require evidence trails (what triggered the score) and a documented dispute workflow.
Drift Control
• Require SOP/KB grounding and versioning, plus an explicit re-audit approach after material rule changes.
• Ask how the partner detects regression (trend monitoring, variance signals), consistent with the reality that AI risks can change over time.
Evidence Trails and Access Control
• Require audit logs/trails that can be shared with your stakeholders, with RBAC.
• Require raw data exportability so you can validate outcomes without vendor lock-in (Flatworld: Power BI reporting + CSV export).
Workflow Embedding
• Confirm how QA outputs feed coaching and reporting routines.
• Confirm how integrations work with your helpdesk/CRM, email, and chat platforms (Flatworld: integration support via APIs and multiple input formats).
Deployment Realism
• Require a timeline and scope boundary you can hold the provider to. A well-governed augmented call center can deploy the QMS workflow “as-is” in roughly a week depending on requirements, which is the kind of concrete timeline you should expect to hear (with caveats).
“Every score and every recommended snippet must be traceable to the model or rule version, the exact transcript segment it used, and who accepted, edited, or ignored it. If a vendor can’t show that lineage on demand, the scores are just vibes.” – Operations Leader, ProMD Health Bethesda
Download the 2026 Vendor Evaluation Checklist Here
Bottom line: In 2026, you’re not choosing a vendor to “run a contact centre.” You’re choosing whether they can run an augmented control system without adding headcount and without turning QA into a constant dispute.
Lean gave you process stability. The 2026 standard asks for something harder: a partner who can run the augmented operating model with the governance, calibration, and evidence infrastructure that makes AI-assisted work defensible, not just fast.
If you are at shortlist stage and need to stress-test whether a vendor’s quality model will hold under real augmentation conditions, the next step is a structured readiness review, not a demo.
AI augmentation only works when it’s governed.
Flatworld’s Call Center Services are designed for organizations scaling agent assist and automated QA—without losing adoption control, scorecard confidence, or visibility into performance drivers.
See how we operate augmented contact centers with built‑in governance, evidence trails, and workflow accountability.
 Prev
Prev
